Data Labeling Industry: Huge Opportunity in the space of Machine Learning
- Mamta Swaroop
- Nov 29, 2023
- 4 min read

Updated: Nov 30, 2023
Presented as a Guest speaker in the One Week Online Faculty Development Programme (FDP) on “Recent Trends & Advancements in the Era of Machine Learning” organised by Department of Computer Science & Engineering, Harcourt Butler Technical University Kanpur, UP during July 19-24, 2021.
The more accurate, clean, and well-labeled training data is provided to a Machine Learning algorithm, the more authentic results are produced. Over 80% of the time spent on AI project is invested in data collection, cleaning, preparation, and labeling phases.
Data Preparation is primarily about –
Correcting bad data
Removing duplicates
Standardizing / formatting data
Updating out of date information
Enhancing / Augmenting data etc.
Data labeling is a specialized step in the process – requires Human intervention
To achieve appropriate results, ML algorithms are first trained over well labeled data -
Cat image identifying application needs to be fed thousands of cat images, labeled as cats
Speech recognition software must be provided accurately labeled transcripts to match audio recordings
Self-driven cars need to identify the objects crossing its path - a plastic bag or a mother pushing a stroller
Train ML Algorithms over Labeled Data
Human intelligence is required to label the images that are fed to the algorithm for the training purpose.
Data labeling for machine learning applications has spawned an entirely new industry.
There are vendors offering labeling services to AI/ML companies.
new opportunity for the people around the globe: human data labelers
offers low-skilled work like identifying “cats” in a video
offers specialized work performed by experts; like a radiologist outlining the exact contours of a tumor on a medical scan or a lawyer identifying a non-compete clause in a contract
opportunities available to outsourcing firms as well as individual freelancers
with such complex data flows, data governance comes in picture: source of data, who is using and for what purpose
Size of the Opportunity
Approximately 10,000 hours of labeled 20-second video clips are required to train a prototype driver distraction algorithm. To make it production ready, it requires 4-5 million hours of video.
Data Collection & Labeling Market Worth $8.22 Billion By 2028
Data labelling is a process that identifies raw data (images, text files, videos, etc.) and adds one or more contextual labels to it so that a machine learning model can learn from it.
Labeling happens in various ways –
bounding boxes around objects
tagging items
classifying items into database
Common Labelling Errors –
labeler’s awareness/unawareness about the object might introduce a bias
labeler might miss placing a bounding box around one of the many objects
bounding box isn’t tight enough around each object, leaving unnecessary gaps around them
labeler places one bounding box around multiple objects, instead of one around each object
labeler places a bounding box around the expected size of a partially-hidden object, instead of placing around only the visible part of the object
Data science team analyzes the labeled data to check for any errors / biases
Used by various ML Applications

Human Data-labelers tag the data. The labeling process can be a simple yes/no or may be as detailed as identifying individual pixels in an image.
Process to create the training data is expensive, complicated, and time-consuming.
Labeling process can be made more efficient by generating a model that can label data automatically. The model is first trained on a set of raw data already labeled by humans. When the new raw data is supplied to model for labeling, it automatically labels the data when the confidence score is high otherwise it leaves data to be labeled by humans. Human-generated labels are then again fed back to the labeling model, to reinforce learning and to improve its ability to automatically label the next set of raw data.
Accuracy of a trained model depends a lot on the accuracy of labeled data used for training purposes.
Labeling – explained through Amazon SageMaker
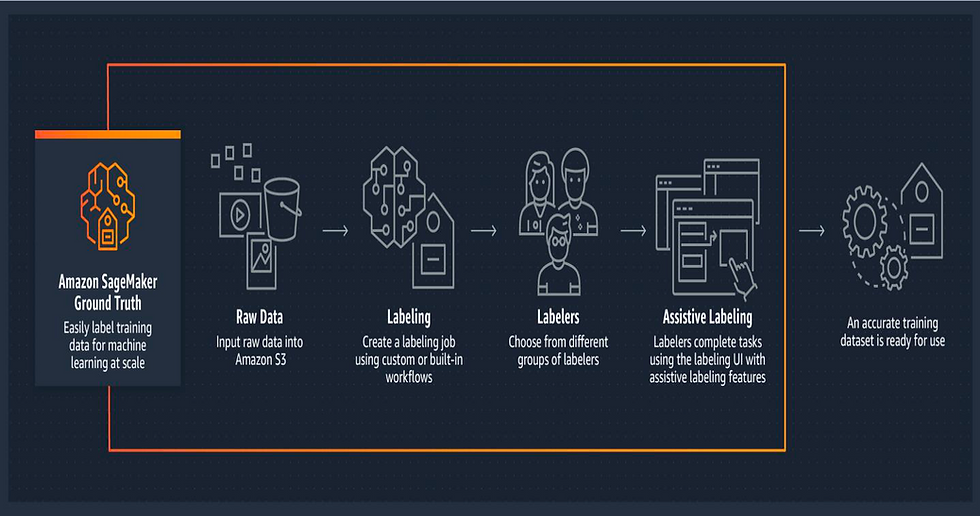
Processes & Best Practices
ML models verify human judgments before they are finalized
ML models provides an initial 'best guess' hypothesis before human labelers start the task
Right tools for images, text, videos labeling.
Right tools for distributing data to labelers so that they can work simultaneously on same data without duplicating
Authorized access to authentic users only
Diverse group of labelers, with right set of domain understanding
Industry Players
- Hive
- iMerit
- Appen
- Toloka
- Amazon
- Scale AI
- Figure Eight
- CloudFactory
India’s Pie
“Its sheer size and prevalence of STEM education mean that there is a vast pool of talents, who could potentially take on data-labelling tasks. We call such people Tolokers. While there are already around 300,000 Tolokers from India and the surrounding region on our platform, we believe that the area’s full potential remains largely untapped.”
~ Olga Megorskaya, CEO
Toloka (a data-labelling service provider incorporated in Switzerland)
Agenda
Teach your models to see like humans, to listen like humans, to talk like humans.
Generate right labels around your textual, audio or video data to teach the models.
References
Comments